配置模型
Hermes 使用两种模型槽位:
- 主模型 — 智能体的思考核心。每个用户消息、每次工具调用循环、每个流式响应都经过此模型处理。
- 辅助模型 — 智能体分发的轻量级任务。包括上下文压缩、视觉(图像分析)、网页摘要、审批评分、MCP工具路由、会话标题生成和技能搜索。每个都有独立槽位,可单独覆盖配置。
本页面涵盖如何从仪表盘配置两者。如果您偏好配置文件或命令行,请跳转至底部替代方法。
Nous 门户在一个订阅下提供300+个模型。全新安装后运行 hermes setup --portal 即可一键登录并将Nous设为您的供应商。使用 hermes portal status 检查连接状态。
- 门户订阅者还可享受代币计费供应商10%折扣。
model: 架构 — 空字符串与映射关系全新安装时的默认配置为 model: ""(空字符串占位符表示"未配置")。首次运行 hermes setup 或 hermes model 时,该键将自动升级为包含 provider、default、base_url 和 api_mode 子键的映射结构——即本页面及 profiles.md / configuration.md 中展示的格式。若在 config.yaml 中看到空字符串,只需运行 hermes model(或在仪表盘点击更改),Hermes 即可自动写入字典格式。
模型页面
打开仪表盘后点击侧边栏的模型。您将看到两个部分:
- 模型设置 — 顶部面板,用于为槽位分配模型。
- 使用分析 — 排名卡片展示选定时段内运行会话的所有模型,包含代币数、成本及能力标签。
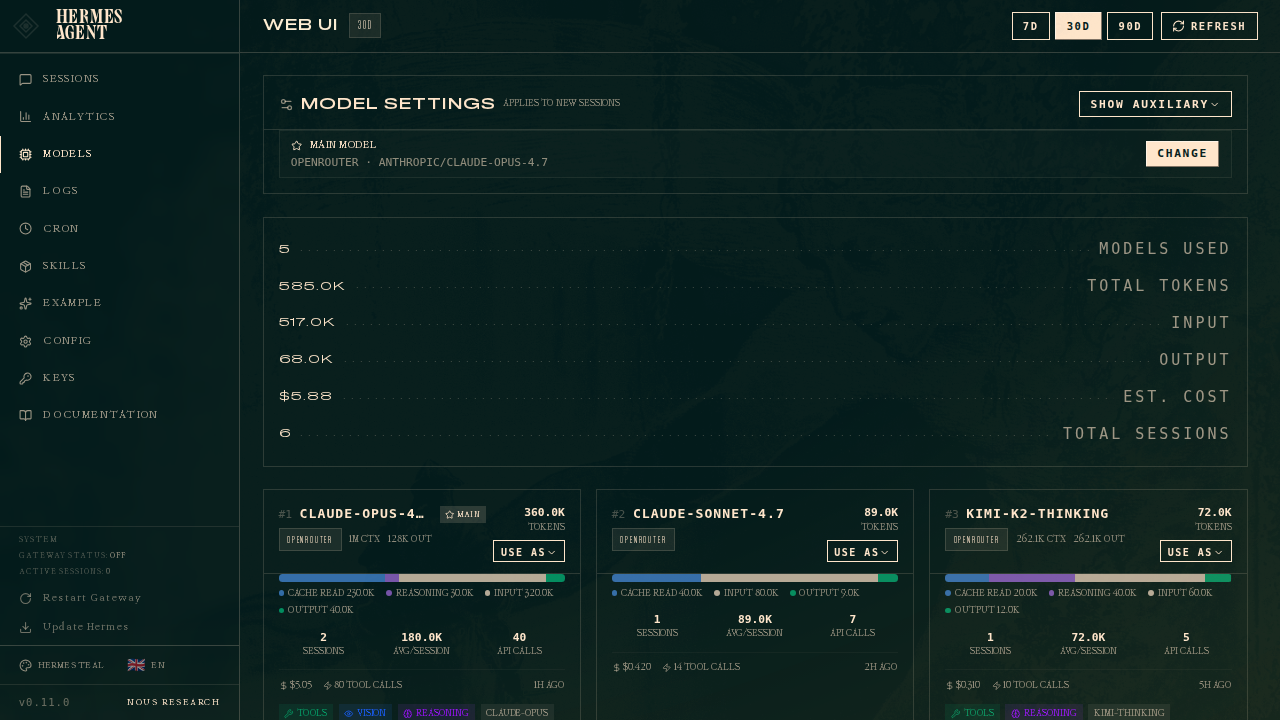
顶部卡片即为模型设置面板。主行始终显示智能体在新会话中将启动的模型。点击更改可打开选择器。
设置主模型
点击 主模型 行的 更改 按钮:
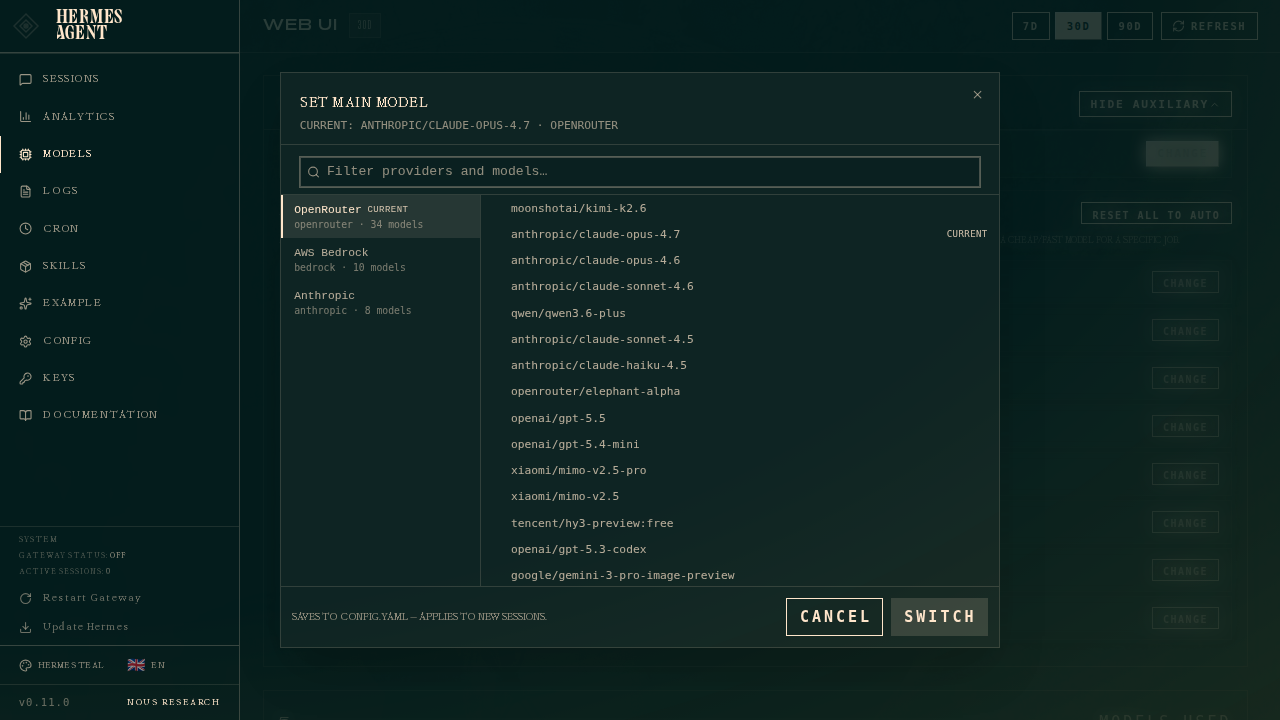
选择器有两列:
- 左侧 — 已认证的服务提供商。仅显示您已配置(设置了API密钥、进行了OAuth授权或定义为自定义端点)的服务提供商。如果缺少某个提供商,请前往 密钥 页面添加其凭证。
- 右侧 — 所选提供商的精选模型列表。这些是 Hermes 推荐用于该提供商的智能体模型,而非原始的
/models数据(在 OpenRouter 上,这包括 400 多个模型,涵盖 TTS、图像生成器和重排序器)。
在过滤框中输入内容可按提供商名称、标识符或模型 ID 进行筛选。
选择一个模型,点击 切换,Hermes 将在 ~/.hermes/config.yaml 的 model 部分写下此设置。这仅适用于新会话 — 您已打开的任何聊天选项卡将继续运行其启动时的模型。要热切换当前聊天,请在其中使用 /model 斜杠命令。
设置辅助模型
点击 显示辅助 以展开八个任务槽位:
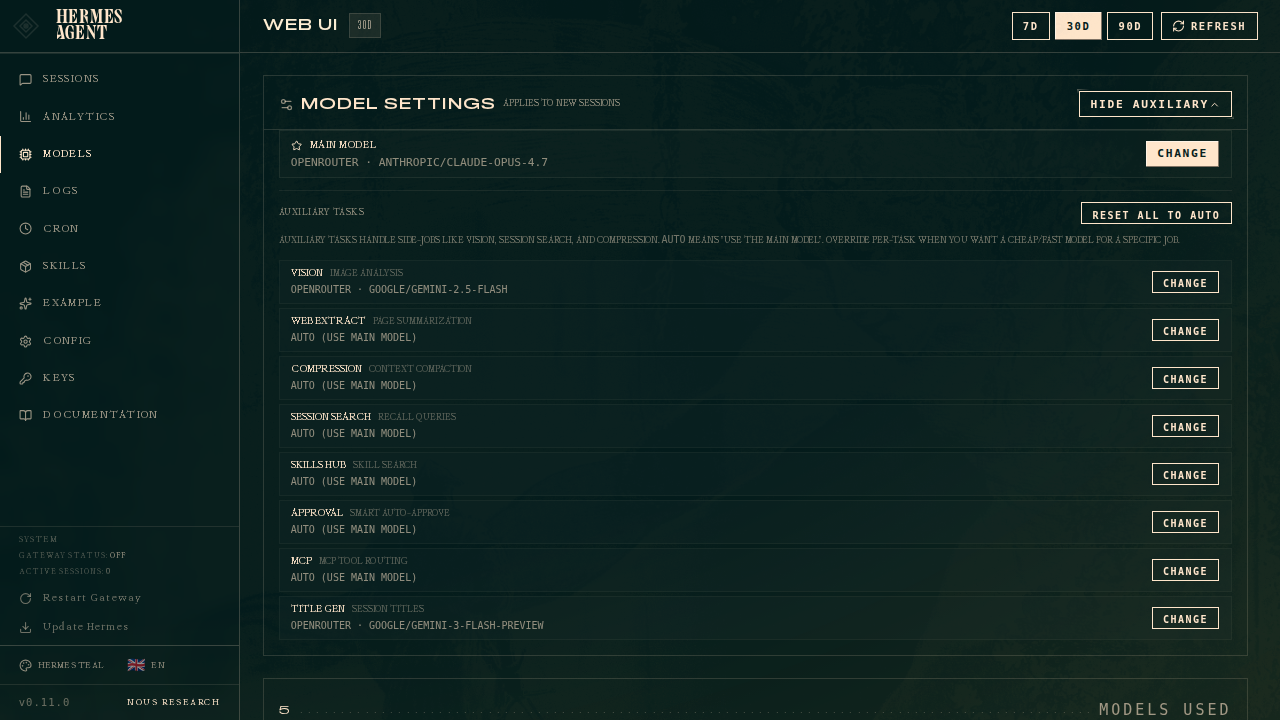
每个辅助任务默认设置为 auto — 意味着 Hermes 也会将您的主模型用于该任务。当您希望为次要任务使用更便宜或更快的模型时,可以覆盖特定任务。
常见覆盖模式
| 任务 | 何时覆盖 |
|---|---|
| 标题生成 | 几乎总是。一个 $0.10/M 的 flash 模型生成会话标题的效果与 Opus 一样好。默认配置在 OpenRouter 上将其设置为 google/gemini-3-flash-preview。 |
| 视觉 | 当您的主模型缺乏视觉支持时。将其指向 google/gemini-2.5-flash 或 gpt-4o-mini。 |
| 压缩 | 当您在 Opus/M2.7 上消耗推理 token 只为总结上下文时。一个快速的聊天模型可以以 1/50 的成本完成此工作。 |
| 审批 | 用于 approval_mode: smart — 一个快速/廉价的模型(haiku, flash, gpt-5-mini)决定是否自动批准低风险命令。此处使用昂贵模型是浪费。 |
| 网页提取 | 当您大量使用 web_extract 时。与压缩逻辑相同 — 摘要不需要推理。 |
| 技能中心 | hermes skills search 使用此模型。通常设置为 auto 即可。 |
| MCP | MCP 工具路由。通常设置为 auto 即可。 |
单任务覆盖
点击任意辅助行的 更改。打开相同的选择器,行为相同 — 选择提供商 + 模型,点击切换。该行将更新显示 提供商 · 模型 而非 auto (使用主模型)。
全部重置为自动
如果您调整过度并希望重新开始,请点击辅助部分顶部的 全部重置为自动。每个槽位都将恢复为使用您的主模型。
“用作”快捷方式
页面上的每个模型卡片都有一个 用作 下拉菜单。这是快速路径 — 在分析中看到一个模型,点击 用作,然后一键将其分配给主槽位或任何特定的辅助任务:
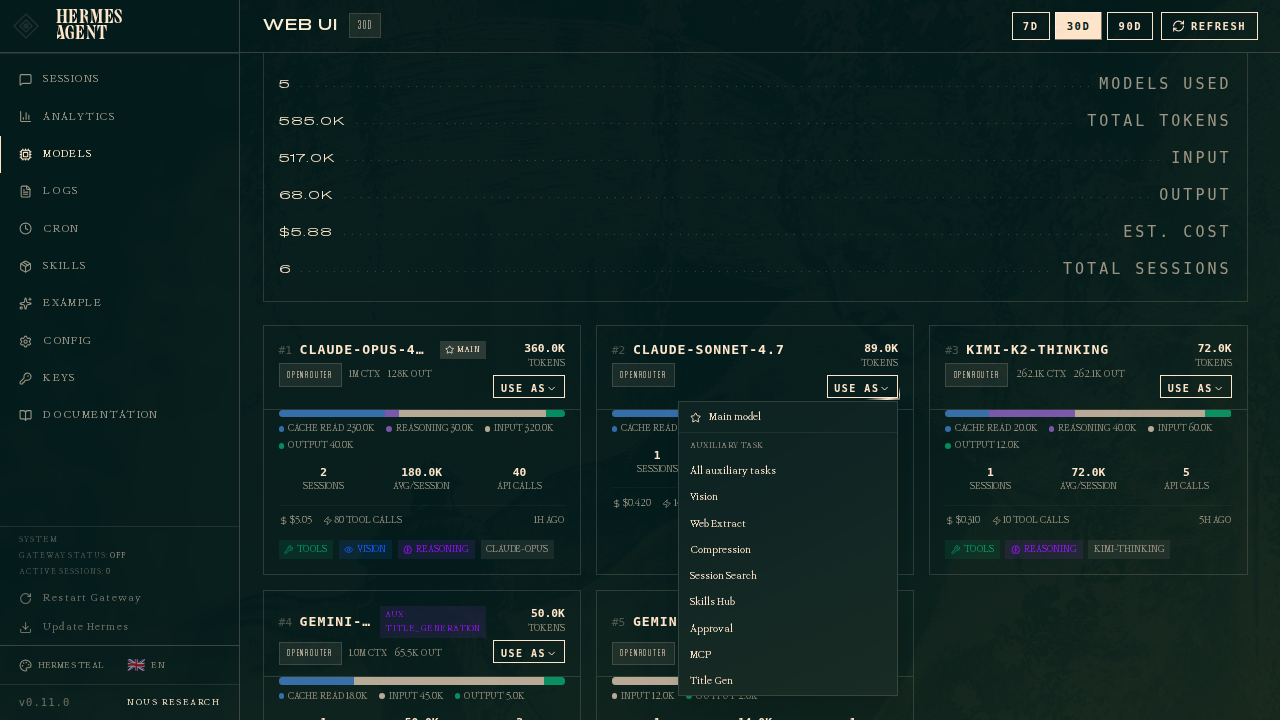
下拉菜单包含:
- 主模型 — 与点击主行的更改相同。
- 所有辅助任务 — 将此模型同时分配给所有 8 个辅助槽位。当您只想将所有次要任务都放在廉价的 flash 模型上时很有用。
- 单独任务选项 — 视觉、网页提取、压缩等。每个任务当前分配的模型标记为
current。
卡片在被分配到某处时会带有 main 或 aux · <任务> 的标记 — 这样您可以一目了然地看到您的历史模型在哪里被使用。
写入 config.yaml 的内容
当您通过仪表板保存时,Hermes 会写入 ~/.hermes/config.yaml:
主模型:
model:
provider: openrouter
default: anthropic/claude-opus-4.7
base_url: '' # 切换提供商时清空
api_mode: chat_completions
辅助覆盖(示例 — 视觉使用 gemini-flash):
auxiliary:
vision:
provider: openrouter
model: google/gemini-2.5-flash
base_url: ''
api_key: ''
timeout: 120
extra_body: {}
download_timeout: 30
辅助设置为自动(默认):
auxiliary:
compression:
provider: auto
model: ''
base_url: ''
# ... 其他字段不变
provider: auto 和 model: '' 告诉 Hermes 将主模型用于该任务。
何时生效?
- CLI (
hermes chat):下次调用hermes chat时。 - 网关(Telegram, Discord, Slack 等):下次新会话。现有会话保留其模型。重启网关 (
hermes gateway restart) 可强制所有会话应用更改。 - 仪表板聊天选项卡 (
/chat):下次新 PTY。当前打开的聊天保留其模型 — 在其中使用/model进行热切换。
更改不会使运行中会话的提示缓存失效。这是故意的:在会话内切换主模型需要缓存重置(系统提示包含特定于模型的内容),我们将此功能保留给聊天中的显式 /model 斜杠命令。
故障排除
选择器中显示“无已认证的提供商”
Hermes 仅列出具有有效凭证的提供商。检查侧边栏中的 密钥 — 您应看到以下之一:API 密钥、成功的 OAuth 或自定义端点 URL。如果所需的提供商不在那里,请运行 hermes setup 进行配置,或转到 密钥 并添加环境变量。
我的运行聊天中主模型未更改
预期如此。仪表板写入 config.yaml,新会话读取它。当前打开的聊天是一个活动的智能体进程 — 它保留其启动时的模型。在聊天中使用 /model <名称> 来热切换该特定会话。
辅助覆盖“未生效”
检查三件事:
- 您是否启动了新会话? 现有聊天不会重新读取配置。
provider是否设置为auto以外的值? 如果该字段显示auto,任务仍使用您的主模型。点击 更改 并选择一个真实的提供商。- 提供商是否已认证? 如果您将
minimax分配给某个任务但没有 MiniMax API 密钥,该任务将回退到 openrouter 默认值,并在agent.log中记录警告。
我选择了一个模型,但 Hermes 切换了我的提供商
在 OpenRouter(或任何聚合器)上,裸模型名称首先在聚合器内部解析。因此,OpenRouter 上的 claude-sonnet-4 变为 anthropic/claude-sonnet-4.6,并保持使用您的 OpenRouter 认证。但如果您在本机 Anthropic 认证上输入 claude-sonnet-4,它将保留为 claude-sonnet-4-6。如果您看到意外的提供商切换,请检查您的当前提供商是否符合预期 — 选择器始终在对话框顶部显示当前主模型。
替代方法
CLI 斜杠命令
在任何 hermes chat 会话中:
/model gpt-5.4 --provider openrouter # 仅限当前会话
/model gpt-5.4 --provider openrouter --global # 同时持久化到 config.yaml
--global 与仪表板的 更改 按钮功能相同,并且它还会就地切换运行的会话。
自定义别名
为您经常使用的模型定义自己的短名称,然后在 CLI 或任何消息平台中使用 /model <别名>。有两种等效格式 — 选择适合您工作流程的格式。
规范形式(顶级 model_aliases:) — 完全控制 provider + base_url:
# ~/.hermes/config.yaml
model_aliases:
fav:
model: claude-sonnet-4.6
provider: anthropic
grok:
model: grok-4
provider: x-ai
短字符串形式 (model.aliases.<name>: provider/model) — 从 shell 中使用很方便,因为 hermes config set 只能写入标量值,但它无法携带自定义的 base_url:
hermes config set model.aliases.fav anthropic/claude-opus-4.6
hermes config set model.aliases.grok x-ai/grok-4
两种路径都馈送相同的加载器 (hermes_cli/model_switch.py)。在 model_aliases: 中声明的条目优先于同名的 model.aliases: 条目。
然后在聊天中使用 /model fav 或 /model grok。用户别名会覆盖内置短名称(sonnet, kimi, opus 等)。完整参考请参阅自定义模型别名。
hermes model 子命令
hermes model # 交互式提供商 + 模型选择器(切换默认设置的规范方式)
hermes model 将引导您完成选择提供商、进行身份验证(OAuth 流程会打开浏览器;基于 API 密钥的提供商提示输入密钥),然后从该提供商的精选目录中选择特定模型。选择将写入 ~/.hermes/config.yaml 中的 model.provider 和 model.model。
要在不启动选择器的情况下列出提供商/模型,请使用仪表板或以下 REST 端点。要检查 CLI 当前实际使用的模型:hermes config get model 和 hermes status。
直接编辑配置
编辑 ~/.hermes/config.yaml 并重启任何读取它的进程。完整模式请参阅配置参考。
REST API
仪表板使用三个端点。可用于脚本编写:
# 列出已认证的提供商 + 精选模型列表
curl -H "X-Hermes-Session-Token: $TOKEN" http://localhost:PORT/api/model/options
# 读取当前主模型 + 辅助任务分配
curl -H "X-Hermes-Session-Token: $TOKEN" http://localhost:PORT/api/model/auxiliary
# 设置主模型
curl -X POST -H "Content-Type: application/json" -H "X-Hermes-Session-Token: $TOKEN" \
-d '{"scope":"main","provider":"openrouter","model":"anthropic/claude-opus-4.7"}' \
http://localhost:PORT/api/model/set
# 覆盖单个辅助任务
curl -X POST -H "Content-Type: application/json" -H "X-Hermes-Session-Token: $TOKEN" \
-d '{"scope":"auxiliary","task":"vision","provider":"openrouter","model":"google/gemini-2.5-flash"}' \
http://localhost:PORT/api/model/set
# 将一个模型分配给所有辅助任务
curl -X POST -H "Content-Type: application/json" -H "X-Hermes-Session-Token: $TOKEN" \
-d '{"scope":"auxiliary","task":"","provider":"openrouter","model":"google/gemini-2.5-flash"}' \
http://localhost:PORT/api/model/set
# 将所有辅助任务重置为自动
curl -X POST -H "Content-Type: application/json" -H "X-Hermes-Session-Token: $TOKEN" \
-d '{"scope":"auxiliary","task":"__reset__","provider":"","model":""}' \
http://localhost:PORT/api/model/set
会话令牌在启动时注入到仪表板 HTML 中,并在每次服务器重启时轮换。如果您要针对运行中的仪表板编写脚本,请从浏览器开发工具 (window.__HERMES_SESSION_TOKEN__) 中获取它。